一、慢 SQL 常见原因
1. 缺少索引(最常见)
导致 Table Scan / Index Scan
数据量越大,性能越差
2. SQL 写法问题
SELECT *
深分页 OFFSET
对索引列使用函数(索引失效)
3. 数据量增长
原有索引不再适配
查询成本指数级上升
4. 参数嗅探(Parameter Sniffing)
执行计划缓存不合理
导致某些参数极慢
5. 锁等待(Blocking)
高并发下事务阻塞
二、标准排查流程(生产推荐)
① CPU 高 → 查高 CPU SQL ② 响应慢 → 查耗时 SQL ③ IO 高 → 查逻辑读 SQL
④ 卡顿中 → 查当前执行 SQL ⑤ 分析执行计划 ⑥ 针对性优化
三、Step 1:找最耗 CPU 的 SQL
SELECT TOP 10 qs.total_worker_time / qs.execution_count AS avg_cpu_time,
-- 平均CPU时间(微秒)
qs.execution_count, qs.total_worker_time,
qs.total_elapsed_time, qs.total_logical_reads,
qs.creation_time, qs.last_execution_time, SUBSTRING(st.text, 1, 500) AS sql_textFROM sys.dm_exec_query_stats
qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) stWHERE qs.execution_count > 0ORDER BY avg_cpu_time DESC;
关注重点execution_count 高 + avg_cpu_time 高持续执行的高频 SQL
四、Step 2:找执行时间最长的 SQL
SELECT TOP 10 qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, --
平均耗时(微秒) qs.execution_count, qs.total_elapsed_time,
qs.total_worker_time, qs.total_logical_reads,
qs.last_execution_time, SUBSTRING(st.text, 1, 500) AS sql_textFROM sys.dm_exec_query_stats
qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) stWHERE qs.execution_count > 0ORDER BY avg_elapsed_time DESC;
建议优先处理 > 1 秒(1000000 微秒)的 SQL
五、Step 3:找 IO 消耗最高的 SQL
SELECT TOP 10 qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
qs.execution_count, qs.total_logical_reads,
qs.total_physical_reads, qs.total_elapsed_time, SUBSTRING(st.text, 1, 500) AS sql_textFROM sys.dm_exec_query_stats
qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) stWHERE qs.execution_count > 0ORDER BY avg_logical_reads DESC;
判断依据逻辑读高 = 大概率全表扫描索引缺失 / 索引失效
六、Step 4:查看当前执行 SQL(实时排查)
SELECT r.session_id, s.login_name,
s.host_name, s.program_name, r.status,
r.blocking_session_id, r.wait_type, r.wait_time,
r.cpu_time, r.total_elapsed_time, r.logical_reads,
r.reads, r.writes, DB_NAME(r.database_id) AS database_name,
t.text AS sql_textFROM sys.dm_exec_requests rINNER JOIN sys.dm_exec_sessions
s ON r.session_id = s.session_idCROSS APPLY sys.dm_exec_sql_text(r.sql_handle)
tWHERE r.session_id > 50ORDER BY r.cpu_time DESC;
判断点blocking_session_id ≠ 0 → 存在阻塞wait_type → 判断等待类型(LCK / IO / CXPACKET)
七、Step 4.1:快速定位阻塞链(生产必备)
SELECT blocking.session_id AS blocking_session_id,
blocked.session_id AS blocked_session_id, blocking.wait_type
AS blocking_wait_type, blocked.wait_type AS blocked_wait_type,
blocking.cpu_time, blocked.total_elapsed_time,
st.text AS blocked_sqlFROM sys.dm_exec_requests blockedJOIN
sys.dm_exec_requests blocking ON blocked.blocking_session_id
= blocking.session_idCROSS APPLY sys.dm_exec_sql_text(blocked.sql_handle)
st;
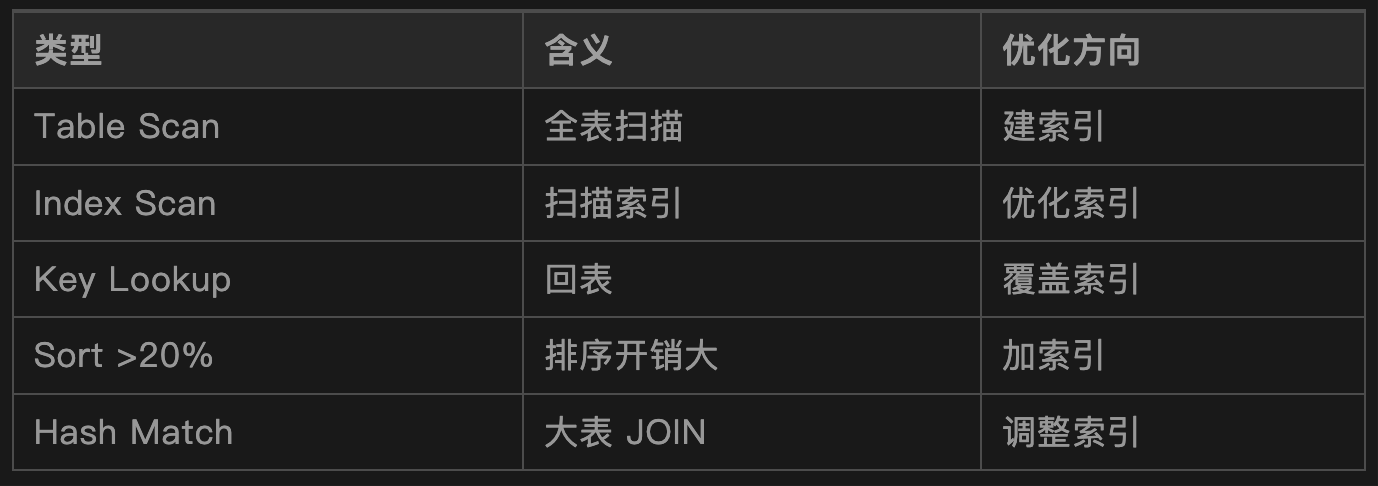
八、Step 5:执行计划分析重点在 SSMS 开启:
重点关注:
Ctrl + M(实际执行计划)
九、实战案例(生产优化)
问题 SQL
SELECT *FROM ordersWHERE create_time = '2024-01-01';
问题
全表扫描
无索引SELECT *
优化方案
-- 创建索引 CREATE INDEX idx_orders_create_timeON orders(create_time);
-- 优化查询(范围查询 + 覆盖索引) SELECT order_id, order_no, status, amountFROM ordersWHERE create_time >= '2024-01-01' AND create_time < '2024-01-02';

十、生产 SQL 规范(必须执行)
1. 查询规范禁止 SELECT *必须走索引字段
2. 索引规范WHERE / JOIN / ORDER BY 必须有索引高频字段优先建立索引
3. 避免索引失效
-- 错误写法 WHERE YEAR(create_time) = 2024 -- 正确写法 WHERE create_time >= '2024-01-01' AND create_time < '2025-01-01'
4. 分页优化
-- 不推荐 OFFSET 100000 ROWS -- 推荐(索引分页) WHERE id > 100000
十一、索引碎片维护(生产建议)
-- 查看碎片率 SELECT OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name, ps.avg_fragmentation_in_percentFROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED')
psJOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_idWHERE ps.avg_fragmentation_in_percent > 10ORDER BY ps.avg_fragmentation_in_percent DESC;
-- 重组(10%~30%) ALTER INDEX idx_name ON table_name REORGANIZE;
-- 重建(>30%) ALTER INDEX idx_name ON table_name REBUILD;
十二、慢 SQL 监控(可直接上线)
-- 创建表 CREATE TABLE slow_sql_log ( id INT IDENTITY(1,1) PRIMARY
KEY, collect_time DATETIME, avg_elapsed_ms BIGINT,
execution_count BIGINT, total_elapsed_ms BIGINT,
total_logical_reads BIGINT, sql_text NVARCHAR(MAX));
-- 采集慢SQL INSERT INTO slow_sql_log ( collect_time,
avg_elapsed_ms, execution_count, total_elapsed_ms,
total_logical_reads, sql_text)SELECT GETDATE(),
(qs.total_elapsed_time / qs.execution_count) / 1000,
qs.execution_count, qs.total_elapsed_time / 1000,
qs.total_logical_reads, SUBSTRING(st.text, 1, 1000)FROM sys.dm_exec_query_stats
qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) stWHERE qs.execution_count > 50 AND (qs.total_elapsed_time / qs.execution_count) > 1000000ORDER BY avg_elapsed_ms DESC;
十三、总结(核心思路)
找慢SQL → 看执行计划 → 查索引 → 优化SQL → 建立监控
关键点
80% 慢 SQL = 索引问题
但以下问题也很关键:
参数嗅探、锁等待、统计信息过期
来源:公众号(作者): sailas